Abstract
Current video generation models perform well at single-shot synthesis but struggle with multi-shot videos, facing critical challenges in maintaining character and background consistency across shots and flexibly generating videos of arbitrary length and shot count. To address these limitations, we introduce \textbf{FilmWeaver}, a novel framework designed to generate consistent, multi-shot videos of arbitrary length. First, it employs an autoregressive diffusion paradigm to achieve arbitrary-length video generation. To address the challenge of consistency, our key insight is to decouple the problem into inter-shot consistency and intra-shot coherence. We achieve this through a dual-level cache mechanism: a shot memory caches keyframes from preceding shots to maintain character and scene identity, while a temporal memory retains a history of frames from the current shot to ensure smooth, continuous motion. The proposed framework allows for flexible, multi-round user interaction to create multi-shot videos. Furthermore, due to this decoupled design, our method demonstrates high versatility by supporting downstream tasks such as multi-concept injection and video extension. To facilitate the training of our consistency-aware method, we also developed a comprehensive pipeline to construct a high-quality multi-shot video dataset. Extensive experimental results demonstrate that our method surpasses existing approaches on metrics for both consistency and aesthetic quality, opening up new possibilities for creating more consistent, controllable, and narrative-driven video content.
Pipeline
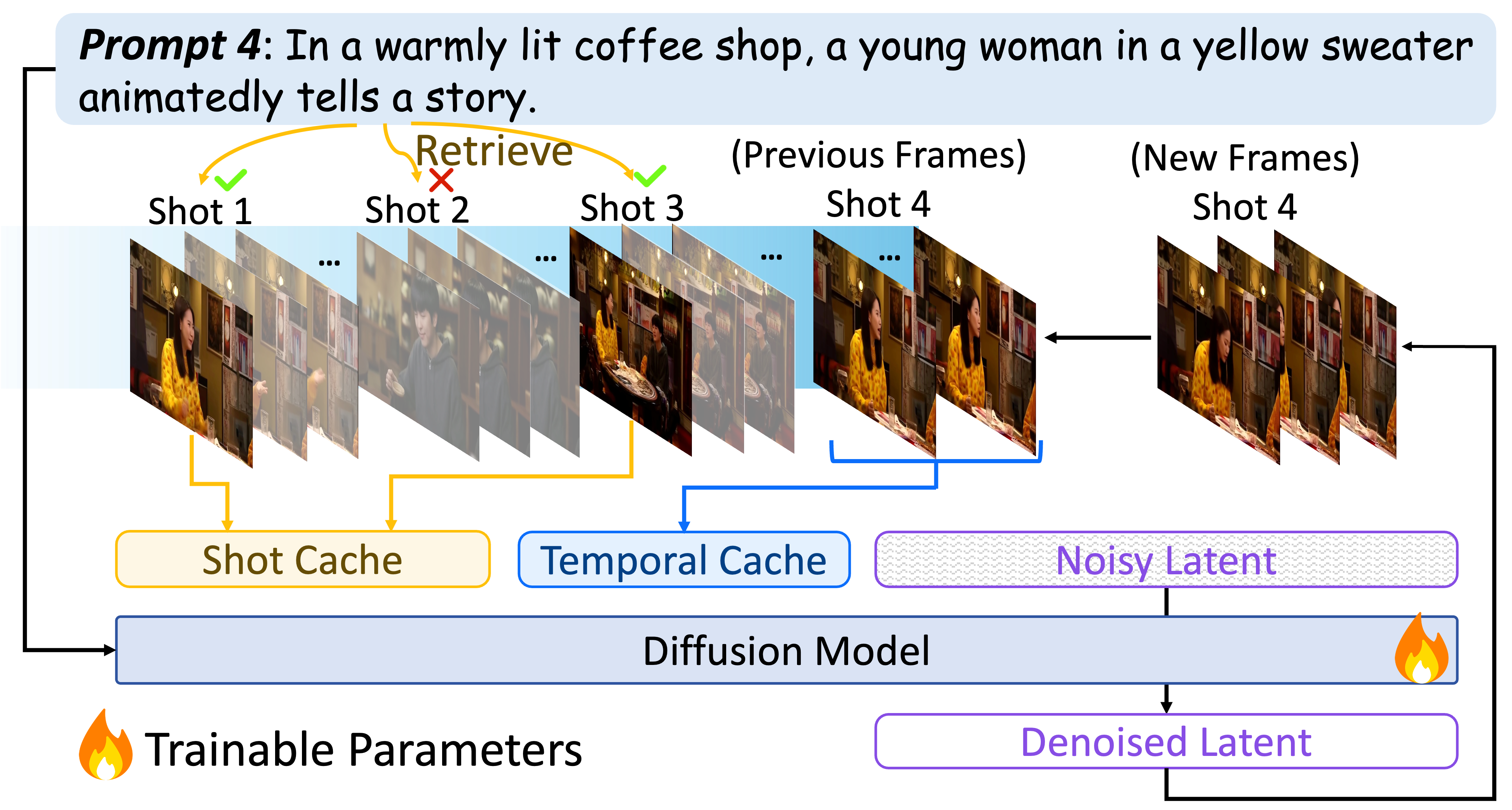
The framework of FilmWeaver. New video frames are generated autoregressively and consistency is enforced via a dual-level cache mechanism: a Shot Cache for long-term concept memory, populated through prompt-based key-frames retrieval from past shots, and a Temporal Cache for intra-shot coherence.
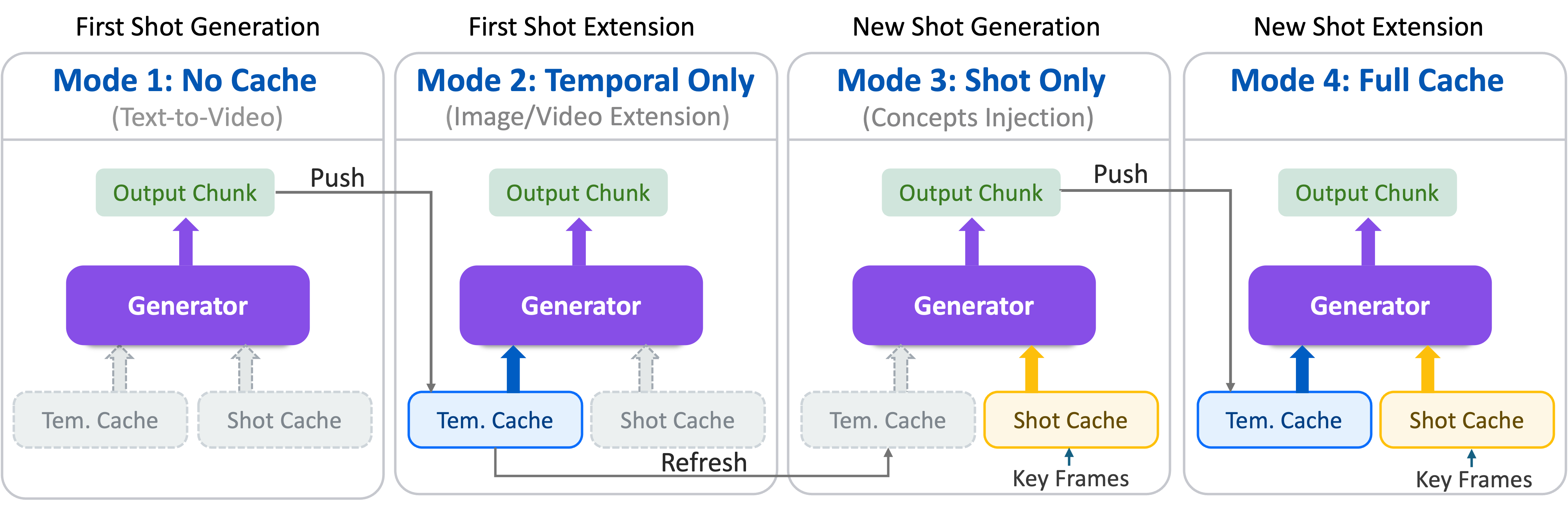
The multi-shot generation process involves four distinct scenarios, each corresponding to a different inference mode: (1) No Cache initializes generation and populates the caches; (2) Temporal Only extends the current shot using temporal context; (3) Shot Only transitions to a new shot by injecting key frames from previous shots; and (4) Full Cache combines both contexts.
Multi-Shot Generation
Qualitative Comparison
More Applications
By editing the two-stage cache contents, our method enables flexible downstream applications: modifying the Shot Cache allows precise concept injection, while adjusting the Temporal Cache supports seamless video extension.
Concept Injection
Our framework can achieve concept injection by manually specifying reference images to insert into the Shot Cache.
Video Extension
By clearing the Shot Cache and switching the text prompt, our framework can extend videos to arbitrary length without introducing new shots.
BibTeX